

Prix et distinctions
Recherche et innovation
Chaire de recherche en génie Marcelle-Gauvreau sur les biomarqueurs mécaniques
Actualités








11 avril 2024
Journée francophone des femmes en informatique

10 avril 2024
Dévoilement des lauréat(e)s de la 1ʳᵉ édition du programme de résidence artistique de l’ÉTS.

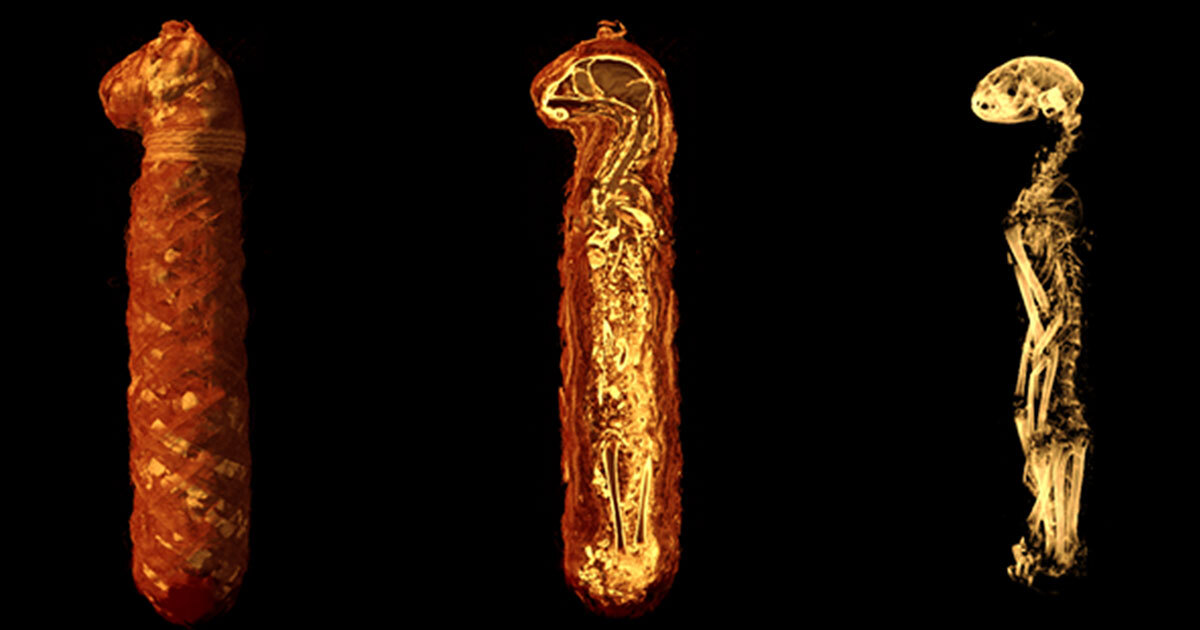

04 avril 2024
Dernier droit pour les stages de l'été 2024!

04 avril 2024
La DCI se classe 2e aux CS Games 2024!

02 avril 2024
Consignes entourant l’éclipse solaire du 8 avril 2024

1
Vous êtes actuellement sur cette page
2
Aller à la page : 2
3
Aller à la page : 3
...
50
Aller à la page : 50
Aller à la page suivante
Explorez votre avenir
universitaire

